Why is this a big deal?
Providing the right context to an LLM is one of the most important aspects of improving your AI application's accuracy of response. Thus, it's no surprise that there's a great amount of focus today on Retrieval Augmented Generation (RAG) based flows inside AI apps. Once you get accurate results from your vector database, there's also another major consideration - that of scale. Your vector database needs to scale really quickly to support RAG use cases from potentially thousands of users. In this article, I will discuss the results of some experiments that I've run to test the concurrency and overall performance of some of the more popular vector database technologies that are available to developers today.
So, What are we testing?
In this test, we're specifically going to test the efficacy of 3 vector database technologies on a single node / single machine. This is the preferred way for deployment of an AI application in a monolithic architecture, plus it also gives us a good idea of how this can scale in other architectures (for example in a serverless one).
This single node test is a good basis for developers to make some decisions on the direction of their AI stack for building applications in its early stages.
A Benchmark of Pgvector, DuckDB, and ChromaDB
In this article, I benchmarked three popular solutions for vector storage and search: pgvector (PostgreSQL), DuckDB, and Chroma. These databases were tested on their ability to handle large-scale embeddings, with a focus on both single-query performance and high-concurrency environments
Data used
The dataset used for this benchmarking was sourced from Huggingface: Infinity Instruct.
It consisted of a total corpus of 2.3GB, containing 470 million tokens.
The speed of ingesting the data into each database was around 10-15 minutes.
-
Embedding model: all-mini-L6-v2
-
Embedding dimensions: 384
-
Chunk Size: Each chunk of text data processed for embedding is approximately 4MB in size
-
Total size of embedded documents (documents + embeddings):
-
Postgres - 1067 MB
-
ChromaDB - 10 GB
-
DuckDB - 4.34 GB
-
Note : The different sizes of the databases - Postgres (1067 MB), ChromaDB (10 GB), and DuckDB (4.34 GB) - stem from variations in storage formats, indexing, and overhead. Postgres uses efficient row-based storage with minimal overhead through the pgvector extension, which helps keep the size low. ChromaDB, specialized for vector operations, incurs more overhead due to its flexible storage and additional indexing structures, leading to its larger size. DuckDB, with its columnar storage and the use of HNSW indexing for vector searches, adds overhead from indexing and in-memory structures, making it larger than Postgres but smaller than ChromaDB. Each database balances storage space and performance differently based on its design focus.
Testing Metrics and Methodology
We performed the same testing methodology for all three databases to evaluate their speed and scalability under concurrent requests.
-
Used Boom for testing the concurrent search APIs.
-
FastAPI endpoint was used for the search.
-
Async mode for executing the queries.
-
Each test involved running 100 queries with 100 concurrent requests.
Results
Chroma
ChromaDB excelled with the fastest response times for a single request. However, when testing 100 queries with 100 concurrent requests using Boom for performance testing, its performance degraded significantly.
Running 100 queries - concurrency 1
\-------- Results --------
Successful calls 100
Total time 39.5288 s
Average 0.3949 s
Fastest 0.3542 s
Slowest 0.5785 s
Amplitude 0.2244 s
Standard deviation 0.033877
RPS 2
BSI :(
Running 100 queries - concurrency 100
\-------- Results --------
Successful calls 100
Total time 40.2357 s
Average 23.0791 s
Fastest 4.0392 s
Slowest 40.2127 s
Amplitude 36.1735 s
Standard deviation 11.237331
RPS 2
BSI :(
Pgvector (PostgreSQL)
For a single query, the performance was 1.9s on average, which was slower than Chroma. However, in the concurrent test, pgvector performed exceptionally well, with an average time of 9 seconds.
Using HNSW index increases the speed of search in milliseconds, which was that helpful. Still we can probably further optimise this result.
Running 1 query -
\-------- Results --------
Successful calls 1
Total time 1.9353 s
Average 1.9329 s
Fastest 1.9329 s
Slowest 1.9329 s
Amplitude 0.0000 s
Standard deviation 0.000000
RPS 0
BSI :(
Running 100 queries - concurrency 100
\-------- Results --------
Successful calls 100
Total time 15.9258 s
Average 9.8094 s
Fastest 3.5887 s
Slowest 15.9031 s
Amplitude 12.3144 s
Standard deviation 3.902037
RPS 6
BSI :(
DuckDB
DuckDB, known for its HNSW index, was tested similarly. Unfortunately, it underperformed for single queries, taking around 23 seconds per call, making it unfeasible for concurrency testing.
Running 1 query -
\-------- Results --------
Successful calls 1
Total time 29.1080 s
Average 29.1044 s
Fastest 29.1044 s
Slowest 29.1044 s
Amplitude 0.0000 s
Standard deviation 0.000000
RPS 0
BSI :(
Running 100 queries - concurrency 100
\-------- Results --------
Successful calls 100
Total time 2716.1324 s
Average 1416.0177 s
Fastest 118.4350 s
Slowest 2716.0860 s
Amplitude 2597.6511 s
Standard deviation 760.306433
RPS 0
BSI :(
Performance Visualization: Metrics and Analysis
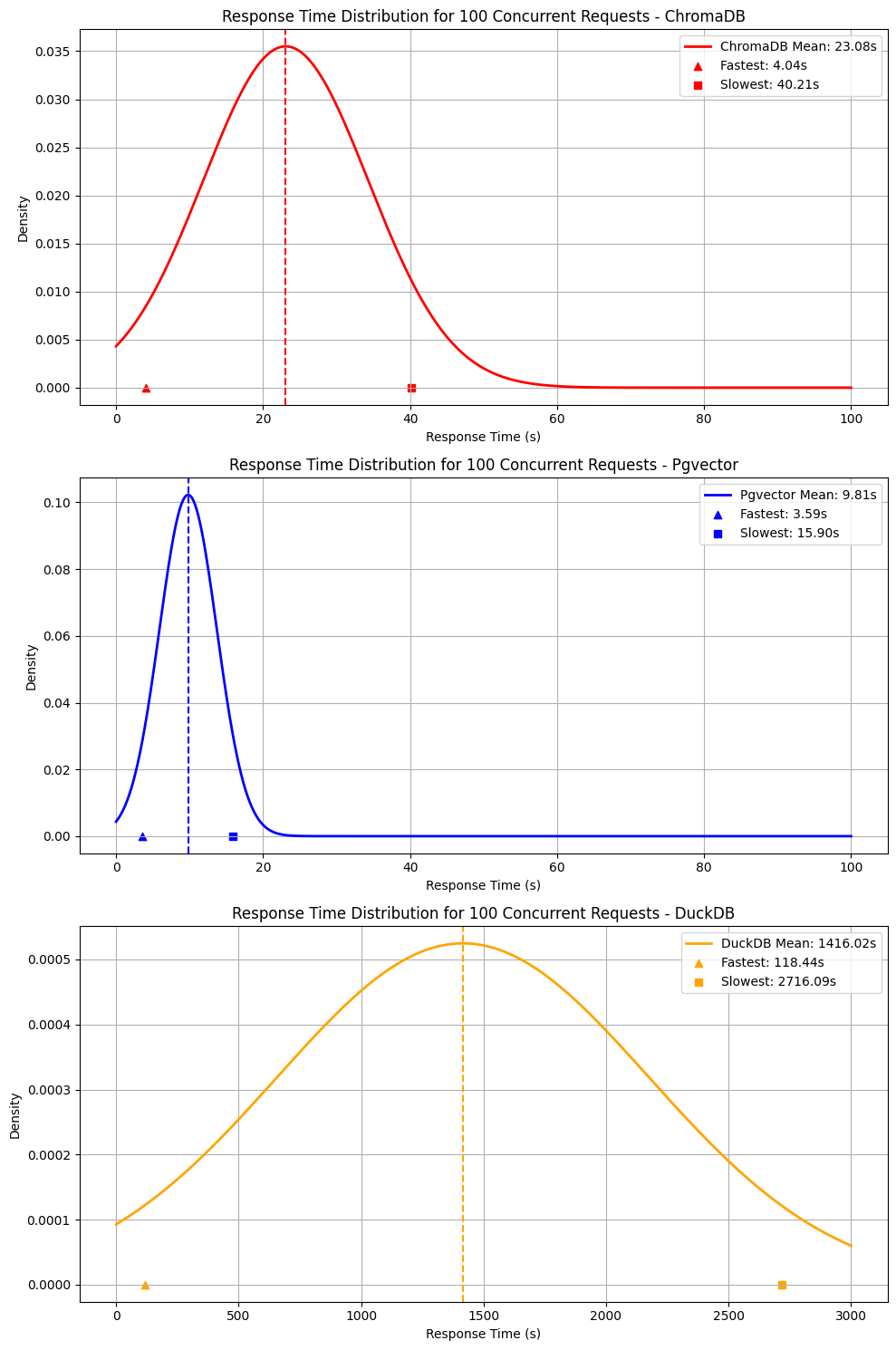
Average Response Time:
Pgvector demonstrates superior performance with an average response time of 9.81 seconds, far outperforming ChromaDB’s 23.08 seconds and DuckDB’s significantly higher 1416.02 seconds. DuckDB’s much slower response time suggests that it may not be optimized for high-concurrency vector queries, despite being a powerful general-purpose database. Pgvector, on the other hand, proves to be more efficient, particularly for low-latency, performance-critical applications, with ChromaDB providing a reasonable alternative, albeit slower.
Fastest and Slowest Requests:
Pgvector recorded the fastest request at 3.59 seconds, outperforming both ChromaDB (4.04 seconds) and DuckDB (118.44 seconds). While Pgvector and ChromaDB deliver fairly quick response times, DuckDB’s slowest query took 2716.09 seconds, highlighting its struggles in handling concurrent requests efficiently. Pgvector’s slowest response of 15.90 seconds shows much more consistency, while ChromaDB’s 40.21-second slowest response indicates it faces more significant performance degradation under certain conditions. DuckDB, however, with its extremely slow fastest and slowest requests, is clearly not suited for real-time or latency-sensitive vector search tasks.
Standard Deviation:
In terms of standard deviation, Pgvector stands out with a low deviation of 3.90 seconds, suggesting a high level of consistency and predictability in its performance. ChromaDB, with a higher deviation of 11.23 seconds, shows greater variability, meaning its response times are less consistent, especially under load. DuckDB’s 760.30-second standard deviation further highlights its unpredictability when dealing with concurrent requests, making it a less reliable option for tasks requiring stable and predictable response times.
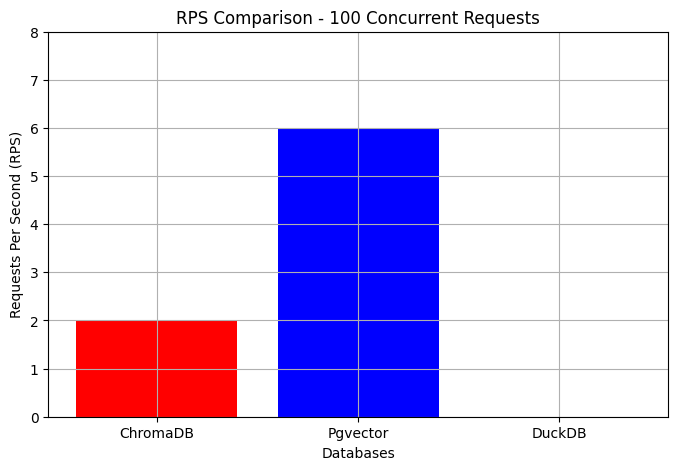
A higher RPS value means the database can handle a larger number of requests simultaneously, making it more scalable for high-traffic applications. So, Pgvector is more suitable for high-concurrency environments. ChromaDB, while slower, may still be suitable for moderate traffic. DuckDB, with an RPS of 0, struggles significantly under concurrent loads, making it unsuitable for high-concurrency environments.
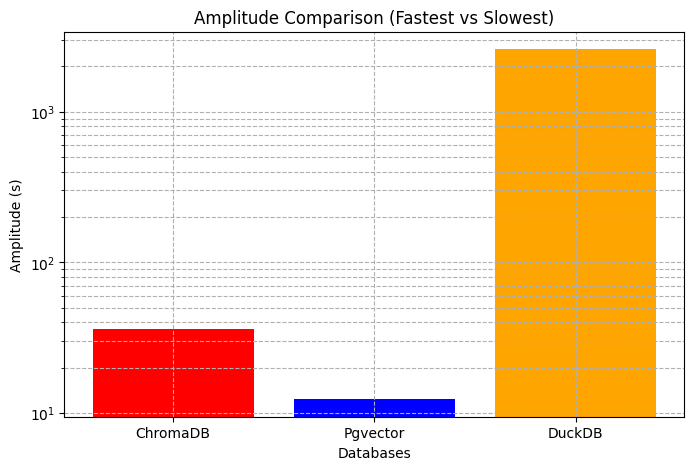
Note : The amplitude comparison is on a logarithmic scale, making it easier to visualize the differences between DuckDB, ChromaDB, and Pgvector without completely flattening the smaller values.
A smaller amplitude signifies that the database performs consistently across different queries, even under concurrent load. In contrast, a larger amplitude suggests that the database may experience performance degradation when handling stress or multiple simultaneous requests.
Thus, Pgvector demonstrated a more predictable and stable performance, while ChromaDB showed greater variability, suggesting it struggles with maintaining consistency under stress. DuckDB, with its significantly larger amplitude, indicates substantial performance degradation under concurrent load. This large amplitude reflects DuckDB's highly inconsistent performance when handling multiple simultaneous requests, making it less suitable for real-time or high-concurrency environments.
Under-the-hood - Why is PGVector faster?
PGVector, built on PostgreSQL, benefits from PostgreSQL’s process-based architecture, where each client connection is handled by a separate backend process. This allows multiple operations, such as reads and writes, to happen concurrently without interference. The postmaster process efficiently spawns and manages these backend processes, ensuring that each user has isolated access to the database, leading to more predictable and stable performance under load.
Furthermore, PostgreSQL’s ability to leverage modern multi-core processors allows multiple backend processes to run in parallel, effectively distributing the workload and utilizing system resources like CPU and memory more efficiently.
In contrast, ChromaDB, which uses SQLite as its underlying database, operates with a file-based architecture that does not support the same level of concurrency. SQLite employs a simpler locking mechanism, where file-level locks are required to ensure data integrity during concurrent operations. This results in significant bottlenecks during simultaneous reads and writes, especially in high-concurrency environments. SQLite’s single-threaded write operations and lack of parallel processing capabilities contribute to its slower performance compared to PGVector, which can manage concurrent connections and operations much more effectively.
Conclusion
Each database has its strengths:
-
Chroma shines for single queries but struggles with concurrency.
-
Pgvector offers solid scalability and high concurrency performance.
-
DuckDB, despite its analytical strengths, is not ideal for vector search performance in this test setup.